Sandra Tan

Having spent a decade in the field of public health, safety & security policies and strategies, I ventured into data science after being intrigued by digital health projects. The projects I have under my belt spans across predictive modeling, NLP, and deep learning, with an emphasis on data-driven impact, especially for a social or health cause. Connect with me if you'd like to chat or discuss anything related to data science!



Hosted on GitHub Pages — Theme by orderedlist
Hi!
Welcome to my growing collection of projects related to data science, machine learning and NLP.
Ingredient detection and recipe recommender
The key aim of this project was for households to utilise existing ingredients and whip up a meal, with a vision of expanding into smart home appliances and/or end-to-end user shopping experience. In 2 weeks, I custom trained a convolutional neural network model (Yolov8m) to detect ingredients from images and suggest Singaporean recipes. I achieved 75% mean average precision across 30 ingredient classes that are common to local recipes. The demo was eventually deployed via FLASK at Pythonanywhere.

[View code at Github] [Demo app at Pythonanywhere]
Tools used: Python, Jupyter, NLP, Roboflow, Google Colab, FLASK
Category: Computer vision, Deep Learning
Year: Aug 2023 (ongoing)
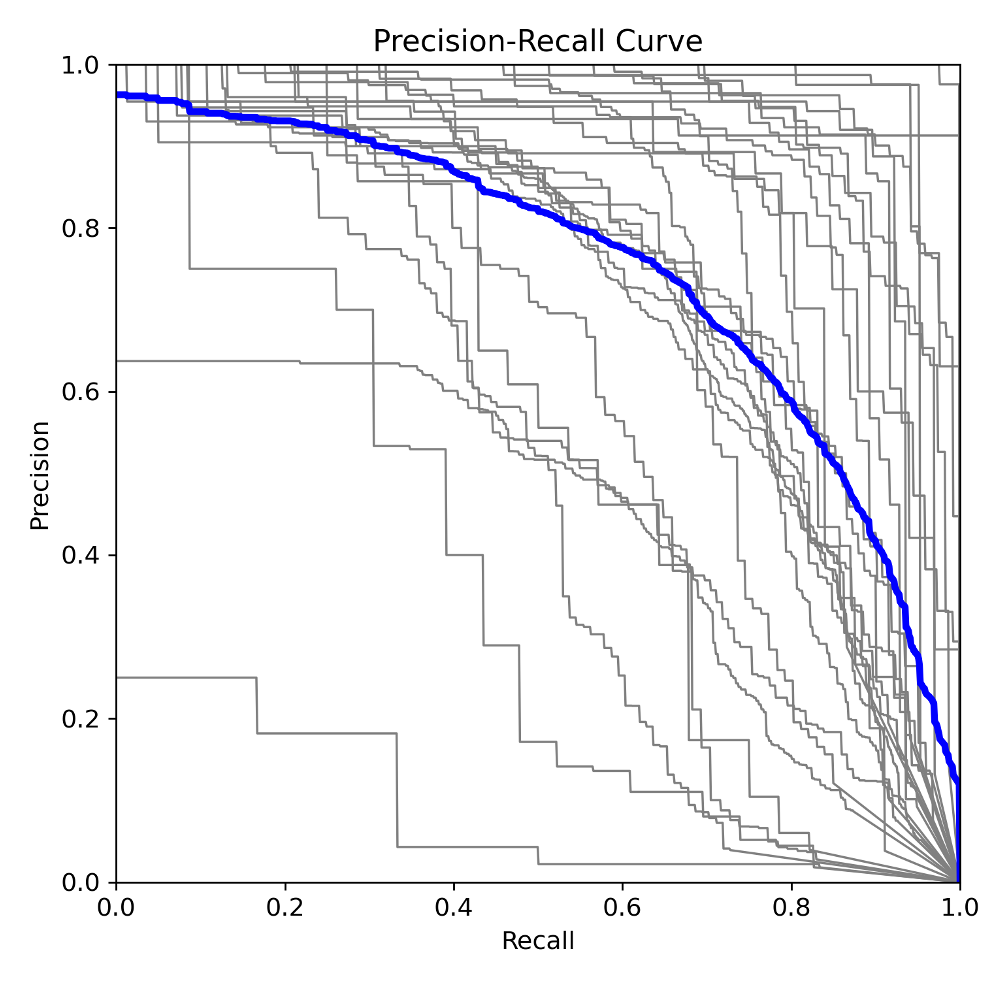
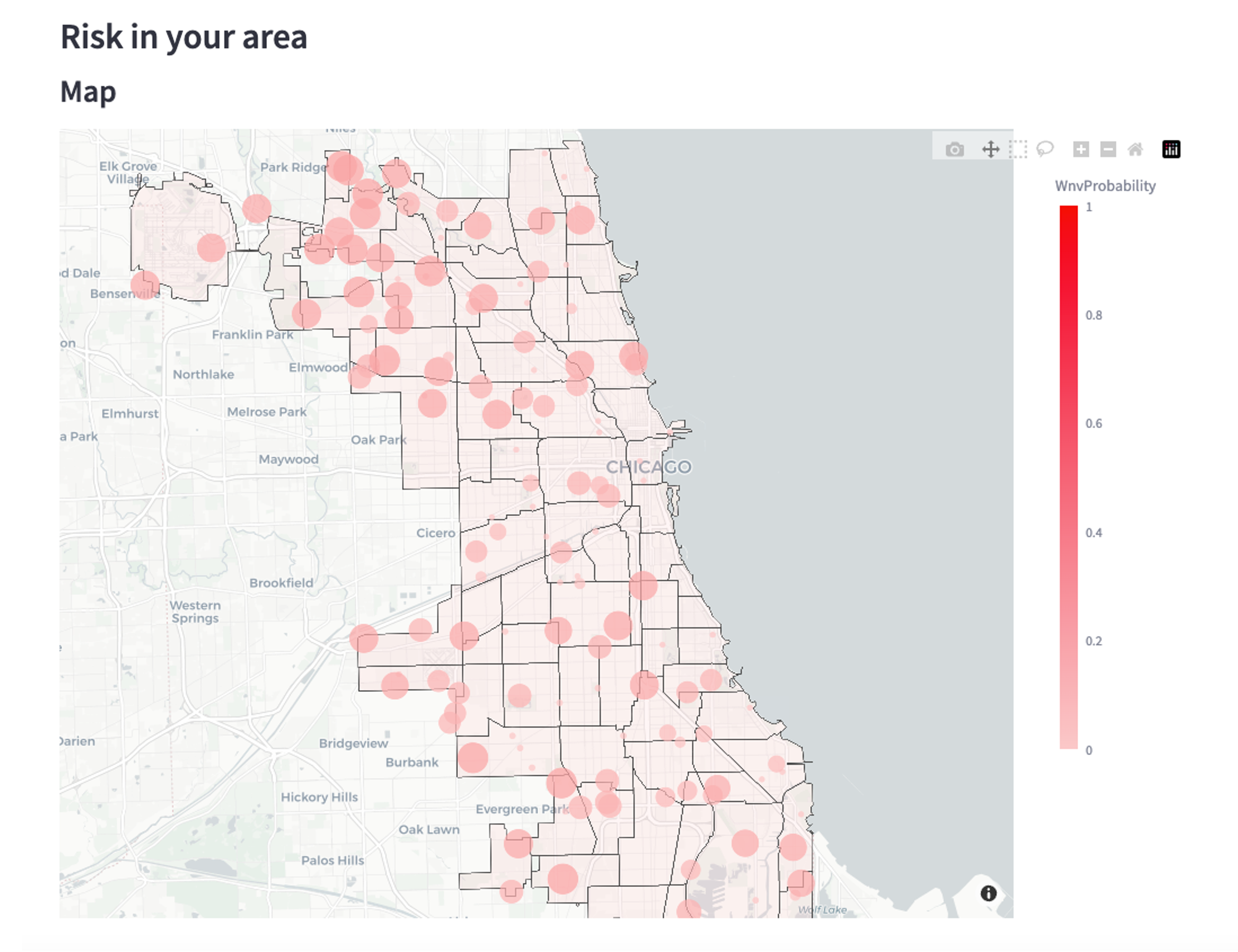
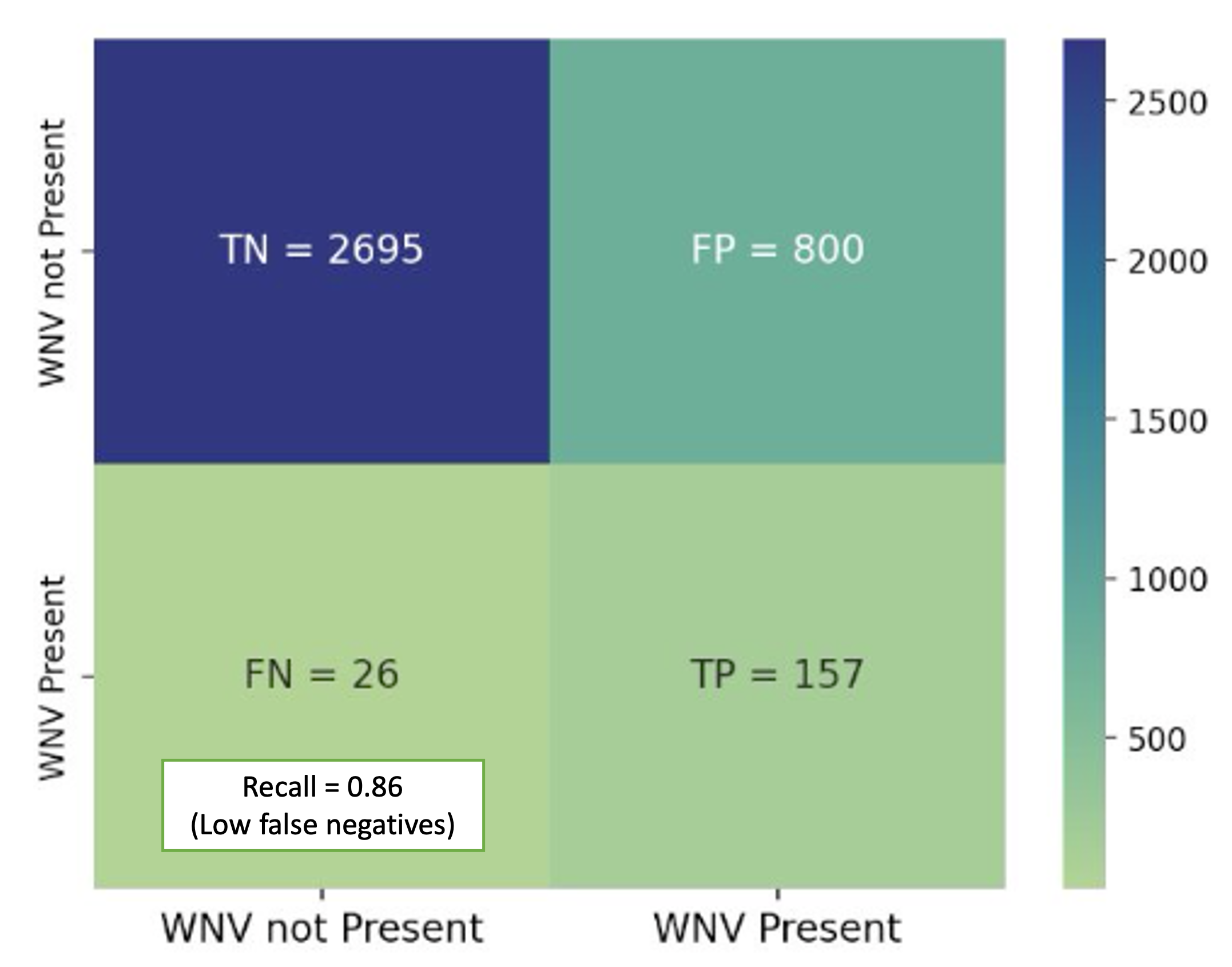
Predicting virus in mosquitoes
The key aim of this project was to predict virus presence in mosquitoes for the city’s ops and resource planning in containing the vector-borne virus. I built a gradient boosted decision tree model, achieving 88% ROC AUC. It was found that weather factors related to “month”, “temperature”, “time of sunset” were strong predictors of virus presence.
[View code at Github] [Demo app at Streamlit]
Tools used: Python, Jupyter
Category: Predictive modelling, Decision trees, Classification, Kaggle Challenge
Year: July 2023
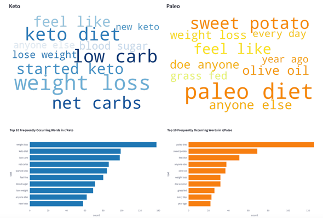
Classifying specialty diet preference using NLP
The key aim of this project was to classify and predict a user’s specialty diet preference based on text inputs. Subreddits for Keto and Paleo diets were scraped, insights extracted, and features extracted for creation of the eventual logistic regression model (93% F1 score). It was found that words like “fat” and “cream” tended to predict Keto over Paleo.
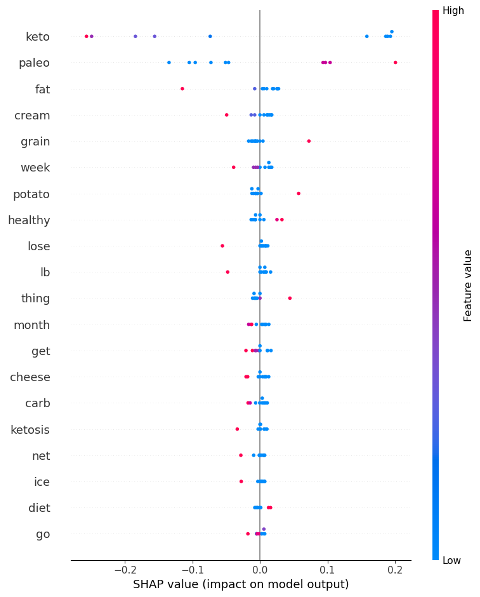
[View code at Github] [Demo app at Streamlit]
Tools used: Python, Jupyter, NLP
Category: Predictive modelling, Logistic Regression, Classification
Year: June 2023
Predicting HDB resale prices
The key aim of this project was to predict Singapore’s HDB resale prices based on historical datasets. A ridge regression model was developed with a 90% accuracy score based on 34 features. A bigger floor area, higher floor and hawker centres nearby were found to be strong positive predictors. Contrary to popular belief, distance to a good primary school was not found to be a strong predictor.
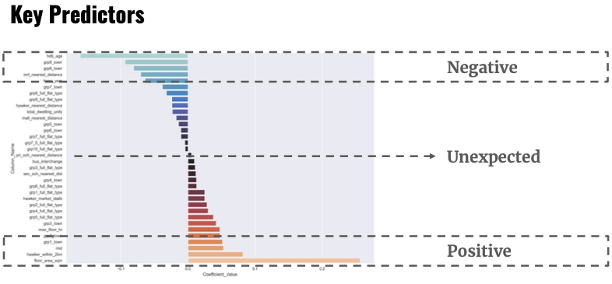
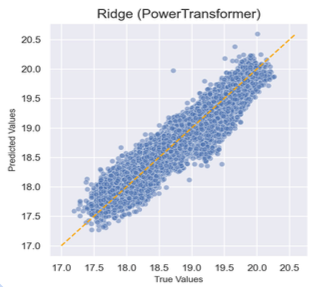
[View code at Github] [Demo app at Streamlit]
Tools used: Python, Jupyter
Category: Predictive modelling, Linear Regression, Kaggle Challenge
Year: May 2023